[Interview] Cache
캐시
캐시(Cache)란?
자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 저장 장소
아래와 같은 저장 공간 계층 구조에서 확인할 수 있듯이 , 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공
- 원본 데이터 접근보다 빠름
- 같은 데이터를 반복적으로 접근하는 상황에서 사용하기에 좋음
- 인증 세션 값과 같은 잘 변하지 않는 데이터일수록 더 효율적

캐시의 등장 배경
- Cache는 나중에 요청할 결과를 미리 저장해둔 후 빠르게 서비스 해줌
- 미리 결과를 저장하고 나중에 요청이 오면 그 요청에 대해서 DB, API를 참조하지 않고 요청을 처리
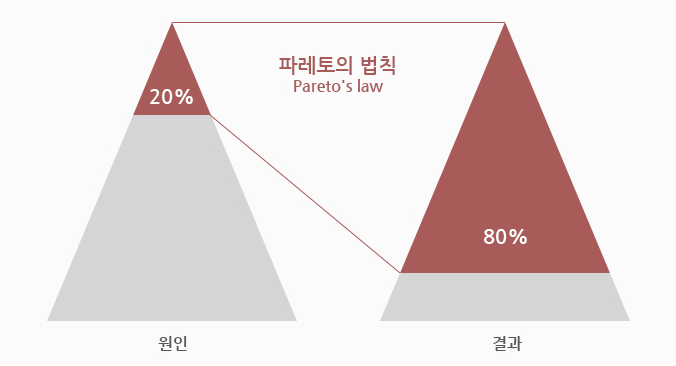
파레토의 법칙(Pareto’s law)
- 80퍼센트의 결과는 20퍼센트의 원인으로 인해 발생(cache가 효율적인 이유)
모든 결과를 캐싱할 필요는 없으며, 우리는 서비스를 할 때 많이 사용되는 20퍼센트를 캐싱한다면 전체적으로 효율을 극대화할 수 있음
어떤 정보를 캐시에 저장하는가?
- 모든 데이터를 캐시에 담기에는 캐시라는 저장공간은 충분하지 않음
- 따라서, 파레토의 법칙에 해당하는 소수의 데이터를 선별 ⇒ 이때 사용되는 것이
지역성
지역성
- 캐시의 지역성은 데이터에 반복적으로 액세스하는 패턴을 나타냄
- 시간적 지역성
- 특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 한번 데이터에 접근할 가능성이 높은 것
- 공간적 지역성
- 특정 데이터와 가까운 주소가 순서대로 접근되었을 경우
- 캐시는 한번에 여러데이터를 저장할 수 있으므로, 주변 데이터까지 함께 캐싱하여 향상된 성능을 제공
- 순차 지역성
- 데이터에 순차적으로 액세스하는 패턴을 나타냄, 이는 순차적인 메모리 주소에 따라 발생
- 이러한 지역성은 캐시의 효율성을 향상시키는데 기여
- 지역성을 활용하여 미래에 액세스할 가능성이 높은 데이터를 미리 캐시에 저장함으로써 빠른 액세스를 제공
- 캐시 교체 정책과도 관련이 있어서 효과적인 캐시전략을 선택하는데 도움이 됨
캐싱 전략
- lazy loading
- read-through
- cache warming
- write-through
- write-back
- write-around
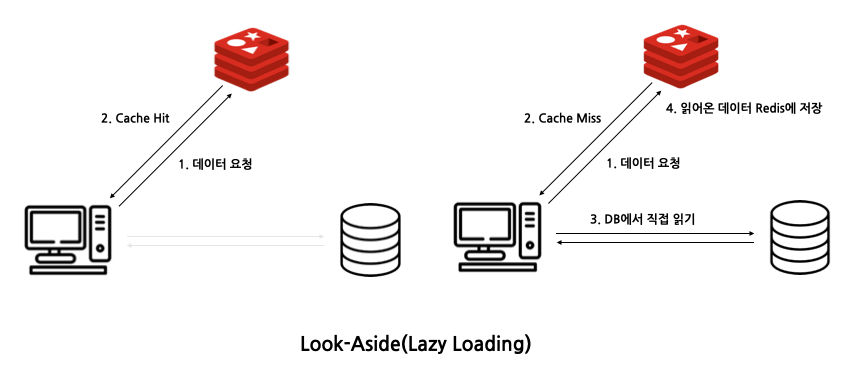
레이지 로딩(Lazy Loading) = Look Aside
클라이언트에게서 데이터가 필요로 해질 때 캐시에 로딩하는 전략
- DB나 API에 접근하기 전 캐시를 먼저 확인 후 캐시에 데이터가 존재한다면 캐시 데이터를 사용
- 그렇지 않다면, 원본에 접근하여 값을 가져와 캐시에 로딩 후 데이터 반환
- 실제로 사용되는 데이터만 캐시 가능
- 초기 부하를 줄이는데 효과적
- 캐시에 없는 데이터를 처리 할 때 더 오랜 시간이 걸림
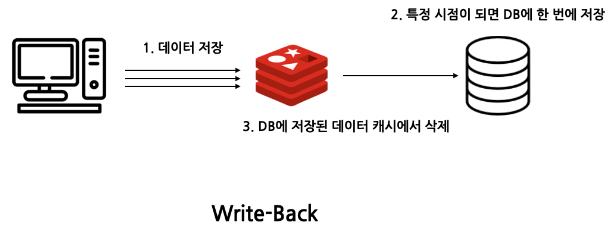
Write-Back
데이터를 전부 캐싱하고 특정 시점마다 캐시 내 데이터를 DB에 업데이트하는 전략
- 여러 번의 요청이 발생할 때 더 빠름
- DB와 캐시간의 데이터 불일치 가능성이 있음 ⇒ 이를 해결하기 위해서 일정 주기나 특정 조건에 캐시의 내용을 DB에 업데이트하는 방법을 사용
1
TTL(Time-To-Live)
캐시에 저장된 데이터가 유효한 시간을 나타내는 속성
- 캐시된 데이터가 얼마나 오랫동안 저장될지 결정
- 일정 시간이 지나면 해당 데이터는 자동으로 만료되고 더 이상 사용되지 않음
- 레이지 로딩 전략에서 TTL을 설정함으로써 자연스럽게 값이 없어지고 캐싱 미스를 일으켜 최신 데이터를 유지할 수 있음
캐시 교체 알고리즘
- 캐시가 사용하는 리소스의 양은 무한대가 아니라 제한적이기 때문에, 캐시는 제한된 리소스 내에서 데이터를 빠르게 저장하고 접근할 수 있어야 함
- 어떤 정보를 오래 저장할것인지를 정해야 함
FIFO(First-In-First-Out)
- 가장 먼저 들어온 데이터를 먼저 제거하는 방식 ⇒ 큐(Queue)와 유사한 동작 방식
- 잦은 교체가 발생 ⇒ 부재율을 높임 ⇒ 실행속도를 저하
LRU(Least Recently Used)
- 메모리에 남아 있는 캐시 중 가장 오랫동안 사용되지 않은 캐시를 새로운 캐시로 교체
- 가장 오랫동안 사용하지 않았던 데이터라면 앞으로도 사용할 확률이 적기 판단
- 데이터 지역성을 높일 수 있음
LFU(Least Frequently Used)
- 데이터의 사용횟수를 기록하고, 가장 적게 사용된 데이터를 제거
- 교체 대상이 여럿이면 LRU 알고리즘에 따름
- 최근 적재된 데이터가 교체 될 수 있음
- 초반에 집중적으로 쓰이고 이후 안쓰인 데이터가 존잰해 메모리 낭비 가능성이 있음
시간 복잡도
O(1)
- 연결리스트로 구현한 lru방식의 삽입 및 삭제
- 연결리스트와 해시로 구현한 lru방식의 탐색
- FIFO방식의 삭제, 삽입, 탐색
O(n)
- 연결리스트로만 구현한 lru방식의 탐색
O(log n)
- 우선순위 큐를 사용한 LFU방식의 삽입, 삭제, 탐색(최소 사용 빈도를 갖는 데이터)
Reference
https://loosie.tistory.com/800
https://velog.io/@tyjk8997/캐시와-궁금한점
https://sabarada.tistory.com/142
This post is licensed under CC BY 4.0 by the author.