[Interview] Stack & Queue
스택, 큐
스택(Stack)이란?
- 후입선출(Last In First Out - LIFO)
- 선형 자료구조
- 큐와 비교됨
- 물건을 쌓아 올리듯 자료를 쌓아 올린 형태
- stack underflow: data가 없을 때 pop
stack overflow: 스택의 크기 이상의 data를 push
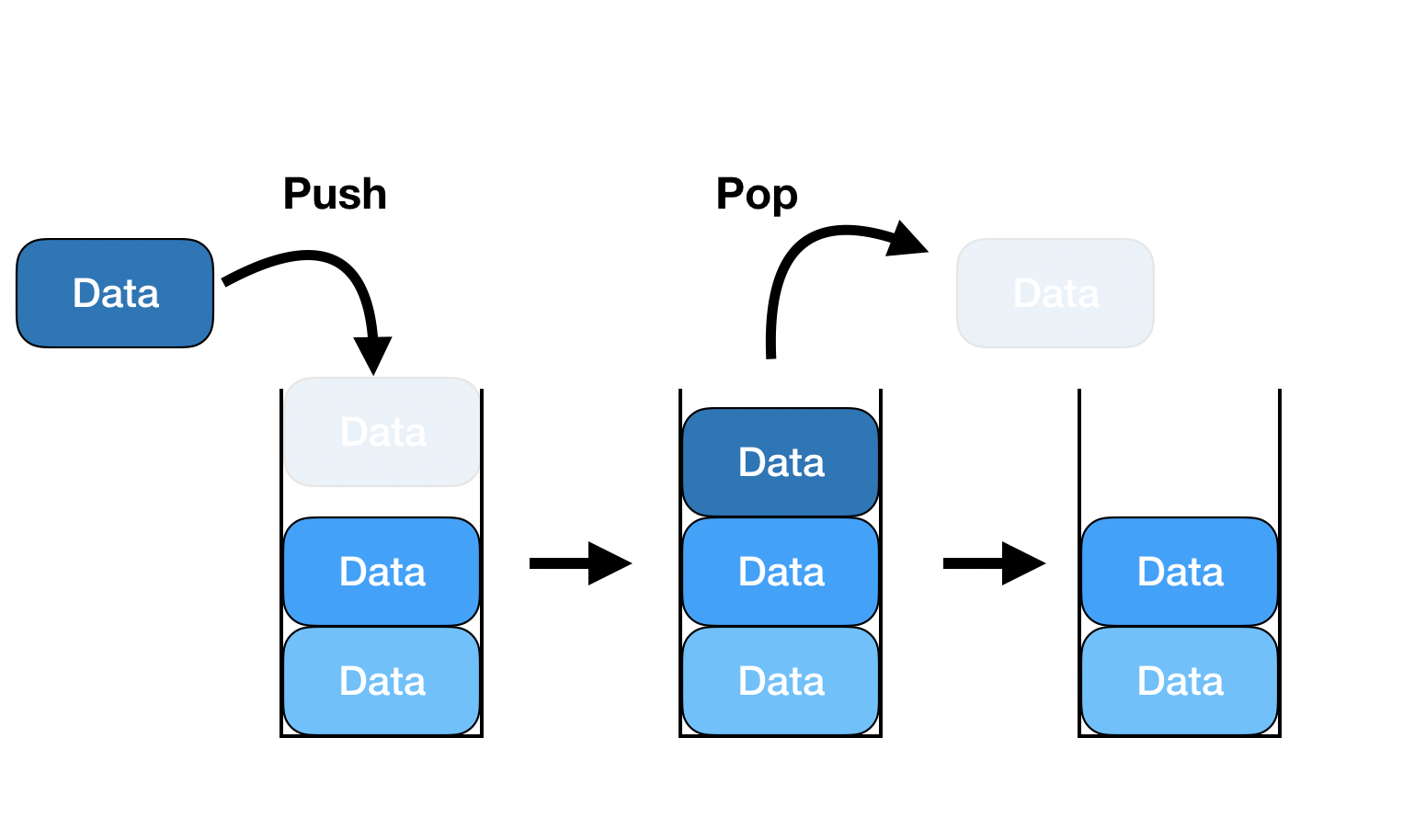
구현
- 배열
- 장점
- 구현이 쉬움
- 배열은 메모리에 연속적으로 저장되어 있으므로 캐시 라인에 데이터가 순차적으로 들어가기 쉬움
- *캐시 히트(Cache Hit) 확률이 높아져서 메모리 접근 속도가 향상
- 단점
- 동적 크기 조절이 어려움, 삽입 및 삭제에서의 배열의 단점
- 장점
- 연결 리스트
- 장점
- 동적 크기 조절이 쉽고, 연결 리스트의 장점을 가짐
- 메모리 공간을 효율적으로 사용 가능
- 단점
- 포인터를 위한 추가 메모리 공간이 필요
- 연결 리스트는 각 노드가 메모리에서 분산되어 저장되므로 캐시 라인에 연속적으로 데이터가 적재되기 어려움
- 캐시 히트 확률이 낮아져서 메모리 접근 속도가 감소할 수 있음
- 장점
**캐시 히트: 캐시 메모리에 찾는 데이터가 존재하는 것*
스택의 사용 사례
- 재귀 알고리즘
- 재귀적으로 함수를 호출해야 하는 경우에 임시 데이터를 스택에 넣음
- 재귀함수를 빠져 나와 퇴각 검색(backtrack)을 할 때는 스택에 넣어 두었던 임시 데이터를 빼 줘야 함
- 스택은 이런 일련의 행위를 직관적으로 가능
- 또한 스택은 재귀 알고리즘을 반복적 형태(iterative)를 통해서 구현 가능
- 웹 브라우저 방문기록 (뒤로가기)
- 실행 취소 (undo)
- 역순 문자열 만들기
- 수식의 괄호 검사 (연산자 우선순위 표현을 위한 괄호 검사)
- Ex) 올바른 괄호 문자열(VPS, Valid Parenthesis String) 판단하기
- 후위 표기법 계산
시간 복잡도
O(1)
- 삽입(push), 삭제(pop), 조회(peek)
- 배열을 사용한 스택에서 index를 알고 있을 경우의 조회
- 배열로 구현한 스택의 크기(size)
- 배열은 메모리에 연속적으로 할당되기 때문에 배열의 크기는 메모리 상의 연속적인 블록의 크기를 알면 계산 가능
O(n)
- 전체 조회
- 특정값 조회
- 연결 리스트로 구현한 스택의 크기(size)
큐(Queue)란?
- 선입선출(First In First Out - FIFO)
- 선형 자료구조
- 스택과 비교됨
- 줄을 선 것과 같은 형태
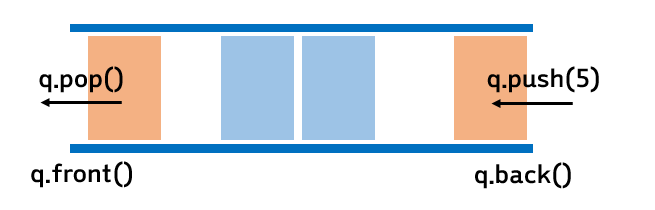
큐의 주요 연산
- Enqueue (인큐)
- 큐에 데이터를 추가하는 연산
- 새로운 데이터는 큐의 뒤(rear)에 추가
- Dequeue (디큐)
- 큐에서 데이터를 제거하고 반환하는 연산
- 가장 앞(front)에 있는 데이터가 제거
- Peek (피크)
- 큐의 가장 앞에 있는 데이터를 조회하지만 삭제하지는 않는 연산
구현
배열 큐
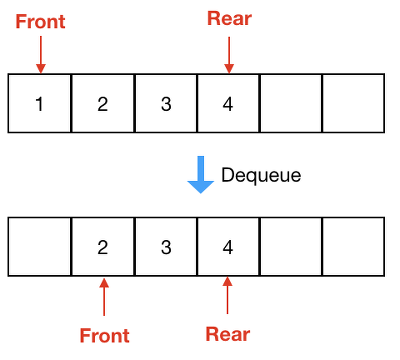
- 뒤쪽은 채워지고 앞은 데이터가 빠져나가는데 이 경우 빈공간이 있지만 데이터에 큐를 넣지 못할 수 있음
원형 배열 큐
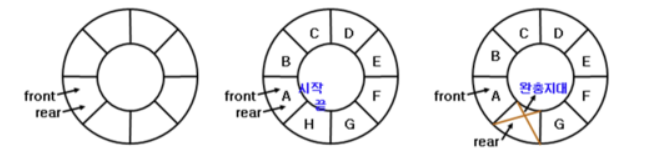
- 배열로 구현된 큐의 문제를 해결하기 위해 원형 배열 큐를 구현
- 배열이 꽉 찬 경우와 배열이 텅 빈 경우 F, R만으로는 구분이 안됨
- 위의 그림처럼 배열이 꽉차거나 텅 빈경우 모두 F, R이 같은 곳을 가리킴
- 위 문제를 해결하기 위해 일반적으로 원형 큐는 배열을 꽉 채우지 않음 배열의 길이가 N이면 데이터가 N-1개 채워졌을 때 이를 꽉찬 것으로 간주
연결 리스트 큐
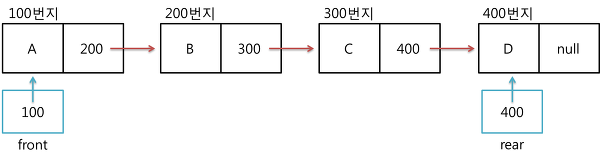
- enqueue는 R이 가리키는 곳 뒤에 새로운 데이터를 추가하고, R이 가리키는 곳을 한 칸 뒤로 옮기면 됨
- dequeue는 F가 다음 노드를 가리키게 하고, F가 이전에 가리키던 노드를 소멸시키면 됨
스택의 사용 사례
- 작업 대기열 (Task Scheduling)
- 다수의 작업이 들어오면 먼저 들어온 작업부터 처리되는 큐를 사용하여 작업을 효율적으로 관리
- 너비 우선 탐색 (Breadth-First Search)
- 그래프에서 가까운 정점을 먼저 방문하는 BFS 알고리즘에서 큐를 사용
- 캐시 관리
- 캐시에서 가장 오래된 데이터를 삭제하고 최신 데이터를 삽입하는 데 큐를 사용
- 스택에 비해 오래된 데이터를 삭제하고 최신 데이터를 삽입한다는 점에서 캐시관리에 더 적합해 보임
- 상황에 따라 다르게 구현 가능
- 컴퓨터 시스템에서의 태스크 스케줄링
- 다양한 태스크를 큐에 저장하고 우선순위에 따라 처리하는 데 큐를 활용
시간 복잡도
O(1)
- 삽입(push), 삭제(pop)
- 큐의 삽입(enqueue)은 항상 front에서만 일어나고 삭제(dequeue)는 항상 rear에서만 일어나므로 삽입과 삭제에 소요되는 시간복잡도는 O(1)로 고정
- 조회(peek)
O(n)
- 큐의 모든 요소 제거 및 특정 연산
그렇다면 시간 복잡도 측면에서 큐가 스택보다 우월해보이는데 스택을 사용할 이유가 있을까?
- 스택과 큐는 각각 다른 응용 분야에서 사용되는 추상 자료 구조이며, 어떤 상황에서 어떤 자료 구조를 선택해야 하는지는 그 사용 목적에 따라 다름
- Last In, First Out (LIFO) 구조 필요
- 스택은 LIFO 구조를 가지므로, 가장 최근에 추가된 요소가 가장 먼저 제거되어야 하는 상황에서 적합
- 예) 함수 호출 시 호출 스택에 현재 실행 중인 함수가 추가되고, 함수가 종료될 때 제거되는 구조에서 스택이 자주 활용
- 재귀 알고리즘
- 스택은 재귀 알고리즘을 구현할 때 유용
- 함수 호출은 스택에 쌓이고, 함수가 종료되면 스택에서 제거됨 따라서 재귀적인 문제 해결에 자주 사용
- Undo 기능
- 사용자의 작업을 스택에 기록하여 Undo 기능을 구현할 수 있음
- 사용자가 어떤 동작을 수행할 때마다 스택에 현재 상태를 저장하고, Undo를 요청하면 스택에서 최근 상태를 꺼내어 적용
- 데이터 역추적
- 어떤 데이터의 변경 이력을 추적할 때, 변경된 데이터를 스택에 기록하는 방식으로 사용할 수 있음
- 이를 통해 특정 시점의 데이터 상태로 되돌아갈 수 있음
Reference
https://juyeop.tistory.com https://dev-coco.tistory.com
This post is licensed under CC BY 4.0 by the author.